🚀 Yapay Zekada Veri Kalitesi Neden Önemli? (Derinlemesine 2026 Rehberi)
Yapay zeka projelerinin büyük bir kısmı başarısız olur. Bunun nedeni çoğu kişinin düşündüğü gibi algoritmaların yetersiz olması değil, kullanılan verinin kalitesiz olmasıdır.
🧠 Gerçek şu:
Yapay zeka modelleri düşündüğümüz kadar “zeki” değildir — sadece verilen veriyi öğrenirler.
Bu yüzden kötü veriyle eğitilen bir model:
- yanlış öğrenir
- hatayı büyütür
- güvenilmez sonuçlar üretir
Kısacası:
👉 Veri kalitesi = Yapay zeka başarısı
📊 Kaliteli Veri Nedir? (Sadece “Büyük Veri” Değildir)
Kaliteli veri, sadece çok sayıda veri toplamak anlamına gelmez.
Asıl önemli olan, verinin doğru, dengeli, güncel ve anlamlı olmasıdır.
Bir yapay zeka modeli şu şekilde çalışır:
📌 Veriyi alır
📌 İçindeki örüntüleri öğrenir
📌 Aynı mantıkla tahmin üretir
Eğer veri hatalıysa:
👉 Model de hatayı öğrenir
👉 Ve bunu sürekli tekrar eder
Bu nedenle veri kalitesi, model performansının temel belirleyicisidir.
🔍 Veri Kalitesini Belirleyen Kritik Faktörler
Yüksek performanslı bir yapay zeka sistemi için veri şu özellikleri taşımalıdır:
🎯 Doğruluk (Accuracy)
Veri gerçeği yansıtmalıdır.
Yanlış etiketlenmiş veya hatalı veri, modelin öğrenme sürecini bozar.
👉 Örnek:
Yanlış etiketlenmiş bir görüntü veri seti, modelin nesneleri sürekli yanlış tanımasına neden olur.
🧩 Tamlık (Completeness)
Eksik veriler, modelin “boşluk doldurmasına” neden olur.
Bu da özellikle tahmin sistemlerinde ciddi hatalara yol açar.
⏱️ Güncellik (Timeliness)
Veri güncel değilse model de güncel değildir.
👉 Eski müşteri davranışlarıyla eğitilmiş bir öneri sistemi, bugünkü kullanıcıyı anlayamaz.
🔄 Tutarlılık (Consistency)
Veri farklı kaynaklarda çelişmemelidir.
Format farklılıkları bile model performansını düşürebilir.
🌍 Çeşitlilik (Diversity)
Veri ne kadar çeşitliyse model o kadar güçlü olur.
👉 Tek tip veri → yanlı model → hatalı sonuçlar
Bu özellikle yüz tanıma, işe alım ve kredi sistemlerinde kritik bir konudur.
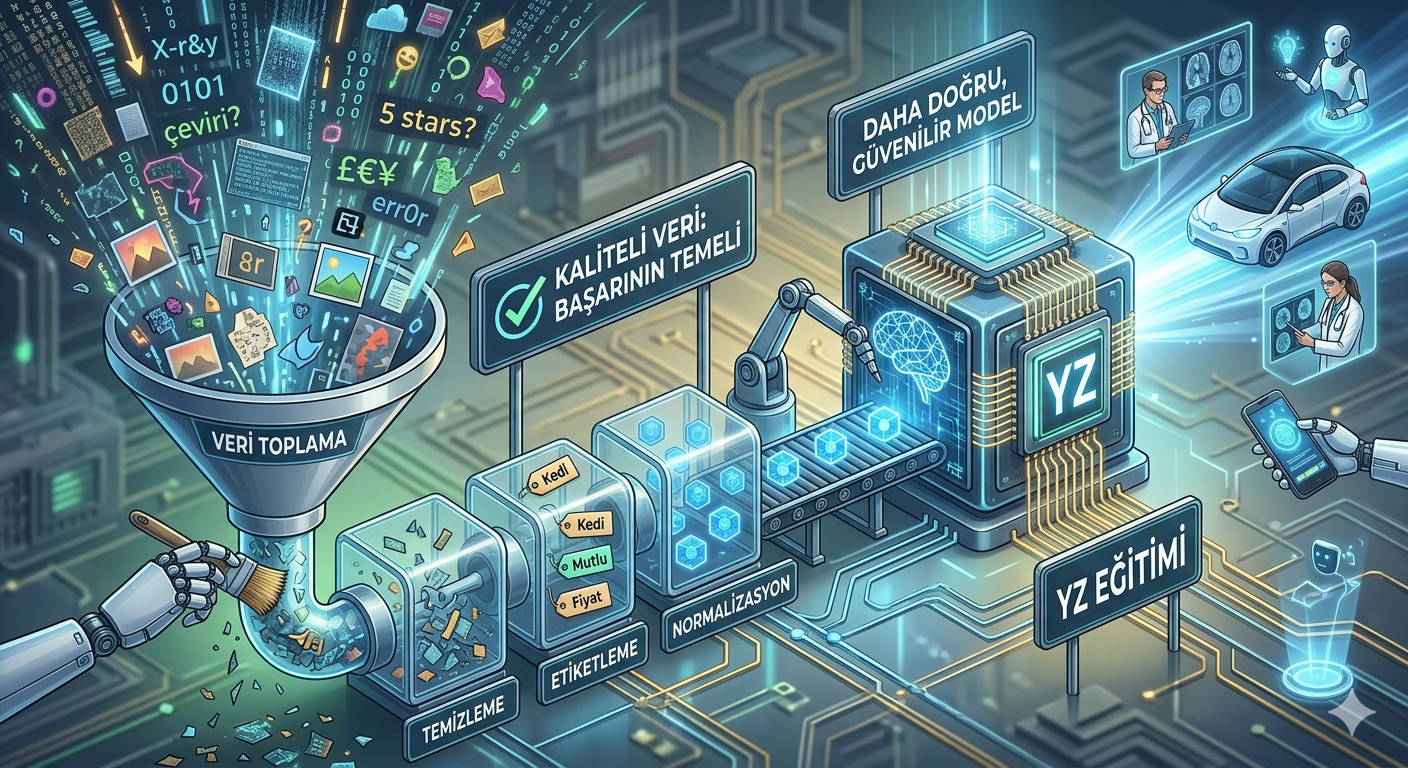
🛠️ Yapay Zeka İçin Veri Hazırlama Süreci (Gerçek Dünya Pipeline)
Başarılı bir yapay zeka sistemi kurmak için veri, aşağıdaki aşamalardan geçmelidir:
1️⃣ Veri Toplama (Data Collection)
Veri farklı kaynaklardan toplanır:
- Kullanıcı etkileşimleri
- Sensör verileri
- API’ler
- Açık veri setleri
📌 Burada en kritik nokta: doğru veri kaynağını seçmek
2️⃣ Veri Temizleme (Data Cleaning)
Bu aşama çoğu projenin kaderini belirler.
Yapılan işlemler:
- Hatalı verilerin silinmesi
- Eksik verilerin doldurulması
- Aykırı değerlerin (outliers) tespiti
- Tekrarlayan kayıtların kaldırılması
🧹 Temizlenmemiş veri = hatalı model
3️⃣ Veri Etiketleme (Data Labeling)
Özellikle denetimli öğrenme için kritik bir adımdır.
Örnekler:
- Görsel → “kedi”
- E-posta → “spam”
- Metin → “pozitif yorum”
📌 Etiketleme hataları, model hatalarının en büyük sebeplerindendir.
4️⃣ Veri Dönüştürme ve Normalizasyon
Farklı veri türleri ortak bir formata getirilir.
Örneğin:
- Sayısal ölçeklerin eşitlenmesi
- Kategorik verilerin kodlanması
📐 Bu adım, modelin veriyi daha doğru işlemesini sağlar.
5️⃣ Veri Bölme (Train / Test / Validation)
Veri genellikle üçe ayrılır:
- Eğitim verisi
- Test verisi
- Doğrulama verisi
👉 Bu sayede modelin gerçek performansı ölçülür.
🧠 Veri Odaklı Yapay Zeka (Data-Centric AI) Yaklaşımı
Yapay zeka dünyasında önemli bir paradigma değişimi yaşanmıştır.
Eskiden:
👉 Daha iyi model = daha iyi sonuç
Şimdi:
👉 Daha iyi veri = daha iyi sonuç
Bu yaklaşım, özellikle büyük teknoloji şirketlerinin benimsediği yeni standarttır.
🤖 Sentetik Veri (Synthetic Data)
Gerçek verinin yetersiz olduğu durumlarda kullanılır.
Özellikleri:
- Gerçek veriye benzer
- Gizlilik sorunlarını azaltır
- Veri eksikliğini giderir
🔁 Veri Artırma (Data Augmentation)
Mevcut veri çoğaltılır:
- Görseller döndürülür
- Gürültü eklenir
- Kırpma işlemleri yapılır
📌 Özellikle deep learning modellerinde büyük fark yaratır.
🎯 Kaliteli Verinin Sağladığı Stratejik Avantajlar
Kaliteli veri sadece teknik bir avantaj değil, aynı zamanda rekabet avantajıdır.
📈 Daha Yüksek Doğruluk
Model, gerçek dünyayı daha iyi öğrenir.
💰 Daha Düşük Maliyet
Kötü modeli düzeltmek, baştan doğru veri toplamaktan daha pahalıdır.
⚖️ Daha Etik ve Adil Sistemler
Bias (yanlılık) azalır → daha güvenilir sonuçlar
🔒 Daha Stabil ve Ölçeklenebilir Sistemler
Farklı senaryolarda tutarlı performans elde edilir.
⚠️ Yapay Zeka Projelerinde En Kritik Hatalar
Projelerin büyük kısmı şu hatalar nedeniyle başarısız olur:
- ❌ Veri kalitesini önemsememek
- ❌ Temizleme sürecini atlamak
- ❌ Yanlış etiketleme yapmak
- ❌ Dengesiz veri kullanmak
- ❌ Güncel olmayan veriyle model eğitmek
👉 Bu hatalar, modelin güvenilmez hale gelmesine neden olur.
🔑 Sonuç: Yapay Zekanın Gerçek Gücü Nereden Gelir?
Yapay zeka sistemlerinde başarıyı belirleyen şey çoğu zaman algoritma değildir.
🚗 Algoritma = motor
⛽ Veri = yakıt
Yakıt kalitesizse:
- performans düşer
- hata artar
- sistem çöker
Ama kaliteli veri kullanıldığında:
- model daha doğru öğrenir
- sonuçlar güvenilir olur
- sistem ölçeklenebilir hale gelir
👉 Bu yüzden yapay zekada en önemli yatırım: veriye yapılan yatırımdır.
💥 Hızlı Özet
- Yapay zekada başarı = veri kalitesi
- Kötü veri = kötü model
- En kritik süreç = veri hazırlama
- Yeni yaklaşım = veri odaklı AI